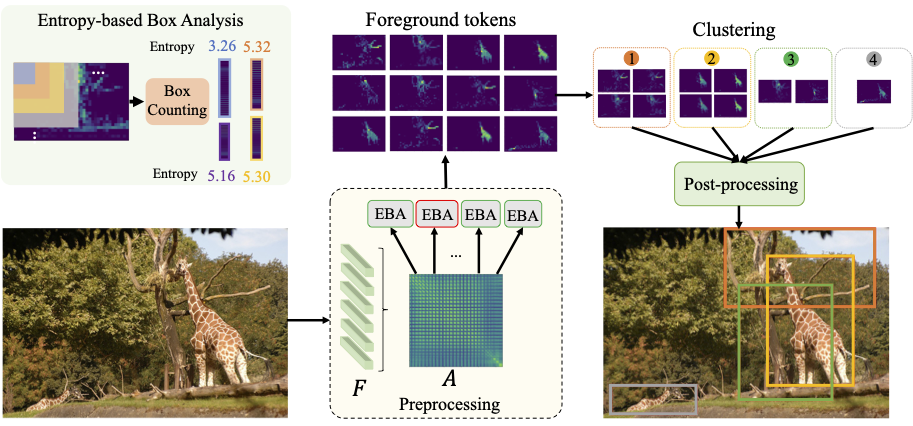
|
MOST can easily be extended for the task of unsupervised saliency detection. We choose the object identified by the largest cluster as the salient object and demonstrate results on DUT-OMRON (Top), DUTS (Middle), ECSSD (Bottom) datasets. Each row shows two examples of input and the output of MOST. In each example, the first image is the input, the second image is the mask generated using the largest cluster, i.e. the output. The third image is the output mask when all the clusters are used and the fourth image is the ground truth. When only one salient object exists in the input (row-1) using all the clusters results in segmenting non salient objects. In the presence of multiple instances of the salient object (row-2), picking the largest cluster results in segmenting only a single instance. Finally, in row-3, we show some failure cases of MOST. Since all the three datasets consists of a majority of images with a single instance, we choose the the mask generated from the largest cluster as our output.
|